Awkward Arrays for Simulated Data#
In this chapter, we will be using Uproot and Awkard arrays to open and work simulated data.
Loading the Data#
First things first: we need the data. Run the following cell to download the simulated data we will be using.
# The ! command is used to run shell commands in a Jupyter notebook or similar environment.
!wget wget https://cernbox.cern.ch/remote.php/dav/public-files/d0FqsjN68SsBlul/uproot-tutorial-file.root
import uproot
file = uproot.open(
"./uproot-tutorial-file.root"
)
file.classnames()
The uproot.open function provides a handle to the ROOT file, but does not actually read any data into memory at this stage. Instead, it allows you to explore the file structure and access its contents on demand. This approach is efficient because it avoids loading large datasets until you specifically request them. For example, after opening the file, you can inspect the available objects (such as TTrees or histograms) and only read the branches or entries you need for your analysis. This lazy-loading behavior is especially useful when working with large high-energy physics datasets.
Now that we have a hande on the ROOT file we want to use, let’s use that to now get a handle on the “Events” TTree.
tree = file["Events"]
tree
Keep in mind that we still have not read any data. Before doing that, its important that we see what is inside the TTree using the show method we learned about in the last chapter.
tree.show()
We can see that it contains some physics observables. Getting some understanding of this data is important for the next steps we will be taking. The folowing table summarizes what each each observable available to us represents.
Column name |
Data type |
Description |
|---|---|---|
|
|
Number of muons in this event |
|
|
Transverse momentum of the muons (stored as an array of size |
|
|
Pseudorapidity of the muons |
|
|
Azimuth of the muons |
|
|
Mass of the muons |
|
|
Charge of the muons (either 1 or -1) |
Here, Muon_phi and Muon_eta refers to the corresponding spacial coordinates used in the CMS coordinate system. The following figure illustrates these coordinates in the CMS experiemnt.
Fig. 6 Coordinate system in CMS#
With this in mind, lets go ahead and finally load some data. We can do this by specifying the TBranch we want through the dict-like interphase of tree and then using the array or arrays method that are provided. For now, however, lets only load some of the data.
# Only loading 100 events
tree["nMuon"].array(entry_start=0, entry_stop=100)
# Alternative: (Not neccessarily the preferred way if you're only interested in loading a single branch)
tree["nMuon"].arrays()
If we wanted to load more than a single branch, we could use the arrays method.
event_data = tree.arrays(["nMuon", "Muon_pt"], entry_stop=100)
print(type(event_data))
print(type(event_data[0]))
Note that what we obtain is rather special and it sort of looks like dictionaries inside an array. The object we are working with is actually an Awkward array, the Awkward library’s equivalent of a NumPy array, which contains Awkard records, the equivalent to a dictionary. This might seem trivial, but this data structure is actually quite powerful. For instance, suppose you want to only get the Muon_pt of this loaded data. To do that, you pass a key value in between brakets to the Awkward array, and you will get in return an Awkward array containing the value for that key for every record/event in that array.
event_data["Muon_pt"]
Note that we are now dealing with a jagged array. We can work with it similarly to how we work with NumPy arrays.*
event_data["Muon_pt"][0:10]
# Note: Only possible if there is at least one Muon in each event. Try with `event_data["nMuon"][:, 0]` to see what happens if we include events with no Muons.
event_data["Muon_pt"][0:10, 0]
Exercise: Print out the \(p_T\) and charge of the muons from events 100 to 115. There are two main ways to do this. Can you figure out what they are? Which method is faster? (Hint: Use the %%timeit magic)
Before moving on to exploring the data, its important to keep something in mind: because the data we typically deal with is quite large, unless neccesary, its good practice to specify the particular TBranches you want instead of doing something like tree.arrays() as this will load in everything, including things you might not be interested in. We already saw one way of loading specific branches, namely:
tree.arrays(["nMuon", "Muon_pt"], entry_stop=100)
Another way would be:
tree.arrays(filter_name=["nMuon", "Muon_pt"], entry_stop=100)
Note that we can also use wildcards in the TBranch filter.
tree.arrays(filter_name="Muon_*", entry_stop=100)
If your TTree has a lot of branches, and show is impractical, you can also use tree.keys, which also accepts filter_name with wildcards. Then you can also verify the data type contained in each column by doing tree.typenames()
# Note: No filtering. But that's okay, because we're not reading data here.
tree.keys()
tree.typenames()
Just like the arrays method, methods accept a filter_name argument.
tree.keys(filter_name="Muon_*")
tree.typenames()
As a last point, for pedagogical purposes, we can also load the data in the form of a Pandas DataFrame, which will highlight the tabular nature of the data. Note, however, that doing this is not usual, and it is usually preferrable to use Awkward Arrays to handle your data.
import pandas as pd
tree.arrays(library="pd", entry_stop=10)
Reconstructing the mass#
Now that we know what the branches look like and what is the data type each one contains, let’s explore the data and try to do something useful with it. Note that the data contains physical observables for muons in each collision event. What would happen if we add the mass of two muons in an event? Let’s find out! First, lets load a sub-set of the events contained in the sample.
# Loading in some data from all branches
muons = tree.arrays(entry_stop=1500)
muons
Just for simplicity, let’s ensure there are two muons in each event. Later on, we will do something more sophisticated. To do this, we can create a filer or mask similarly to how we created masks for NumPy arrays. What we want is for mask to be True when an event has exactly 2 events, and False otherwise. Fortunately, we have the field nMuon which immediately provides us with the information we need to construct this mask as follows.
# If an event has 2 muons, its corresponding element in the mask is True. False otherwise.
mask = muons["nMuon"] == 2
mask
We can now apply this mask the exact same way we applied masks with NumPy array!
# Only keeping di-muon events
dimuons = muons[mask]
dimuons
We can make sure that the resulting filtered array only has events with two muons by using the function ak.all provided by Awkward. This function takes in an array of booleans (although not neccesary that the elements are booleans), and tells you whether all elements are True. This would be equivalent to applying the AND boolean operator over the whole array.
import awkward as ak
ak.all(dimuons["nMuon"] == 2)
Let’s now get the observables into their own variables for future convenience.
# Getting the eta, pt and phi of each of the muons in the dimuon events
pt0 = dimuons["Muon_pt"][:,0]
pt1 = dimuons["Muon_pt"][:,1]
eta0 = dimuons["Muon_eta"][:,0]
eta1 = dimuons["Muon_eta"][:,1]
phi0 = dimuons["Muon_phi"][:,0]
phi1 = dimuons["Muon_phi"][:,1]
Let’s assume the two muons came from the decay of a particle \(A\). We make use of the fact that the square of the total 4-momentum of the system is an invariant quantity to establish that
where the left side comes from the initial state of the system, in an inertial reference frame where the \(A\) is stationary, and the right side corresponds to the final state of the system (i.e., when we have two muons) in the lab reference frame. This reduces to:
which, under the assumption that \(E \gg m\) (i.e., \(E^2 = p^2 + m^2 \approx p^2\)), and changing the coordinates this equation is written in, this reduces to:
We can then use this equation to compute the mass of the hypothetical particle these pairs of muons came from. This is easy to do with Awkward arrays!
import numpy as np
mass = np.sqrt(2 * pt0 * pt1 * (np.cosh(eta0 - eta1) - np.cos(phi0 - phi1)))
mass
Exercise
The dimuon array we constructed to reconstruct the mass only has a single filter applied to it which makes sure there are exactly two muons in each event. Why is this a problem? What other things might we want to ensure from the muons that we will use to reconstruct the mass of \(A\) particle?
The raw data for the reconstructed mass is difficult to interpret without an effective way to visualize it. One of the most common tools in a high energy physicist’s toolkit is the histogram. Histograms display the frequency of data values within specified ranges (bins). This allows us to see the distribution and identify features such as peaks or tails in the data and will make it much easier for us to understand the underlying physics represented by the reconstructed mass values.
To make the histogram, we will use the Hist library, one of the many tools offered by Scikit-HEP. This library offers a user-friendly API for the Boost-histogram Python library which offers a highly efficient and flexible histogramming framework. You can find detailed information about this libarry in the documentation, which you can access through this link: link.
In addition, to easily make our plot look pretty and to follow the conventions used in HEP publications, we will use the mplhep library, also from Scikit-HEP. This library provides convenient plotting styles and functions for HEP data, making it straightforward to produce publication-quality figures that match the look and feel of experiments like CMS or ATLAS. By combining Hist for efficient histogramming and mplhep for styling, we can quickly generate insightful and professional plots of our reconstructed mass distributions.
Under the hood, Hist actually uses Matplotlib to render plots, which means we can take advantage of all the customization and flexibility that Matplotlib offers. Thus, we will import Matplotlib as well to get full access to the plotting tools that this library has to offer.
import hist
import matplotlib.pyplot as plt
import mplhep as hep
hep.style.use("CMS")
Let’s create a histogram object (i.e., hist.Hist) with a single axis. We do this as follows.
masshist = hist.Hist(
hist.axis.Regular(120, 0, 200, label="Mass [GeV]", name="mass"),
)
If we were to plot the histogram right now, we would see that it would be empty, as we have not put any data into it.
masshist
To add our data, we use the fill method and pass the array of the reconstructed masses we made. This method immediately returns the histogram, from which we can get a glimpse of how it looks like.
masshist.fill(mass)
To make a proper plot of this histogram, we will use Matplotlib to create a figure with an axis, and then use the plot1d method of the hist.Hist object to plot the histogram we have created on those axis.
# Using Hist + Matplotlib
fig, ax = plt.subplots()
masshist.plot1d(
ax=ax,
label="Dimuon mass [GeV]",
)
# Adding label for the y-axis
ax.set_ylabel("Count")
# Adding axis title
ax.set_title("Dimuon Mass Distribution")
# Adding legend
ax.legend()
# Show the plot
plt.show()
From this plot, we see multiple peaks. Notice, however that there is a peak very near \(90 \text{ GeV}\). This corresponds to the mass of the Z boson, and it means that we have been able to reconstruct its mass even though our approach was quite rudimentary. We can confirm the exact value for the mass of the Z boson by using the particle Particle library which provides particle data from the Particle Data Group (PDF website). We will also use the hepunits library which provivdes units and constants for the HEP system of units.
import particle
from hepunits import GeV
# Getting the mass of the Z boson
z_mass = particle.Particle.from_name("Z0")
print("Z boson mass in GeV:", z_mass.mass / GeV)
We can also make the previous histogram, but now lets add a vertical line on the Z mass for emphasis.
# Plotting a a vertical line at the Z boson mass
# Using Hist + Matplotlib
fig, ax = plt.subplots()
masshist.plot1d(
ax=ax,
label="Dimuon mass [GeV]",
)
ax.set_ylabel("Count")
ax.set_title("Dimuon Mass Distribution")
ax.legend()
ax.axvline(z_mass.mass / GeV, color="red", linestyle="--", label="Z boson mass")
ax.text(z_mass.mass / GeV + 2, 30, "Z boson mass", color="red", rotation=90, fontsize=16)
plt.show()
While we have been successful at reconstructing the mass of the Z boson to some extent, our approach is quite basic. First, we excluded many events that have more than two muons, even though some of these events might contain two or more muons that originated from a Z boson. Additionally, we did not ensure that quantities such as charge were conserved. We simply added the masses of the muons without verifying these important details. We will address these considerations in the next chapter. For now, lets review once again the code we have developed so far for reconstructing the masses.
# Loading data
muons = tree.arrays(filter_name="/nMuon|Muon_(phi|eta|pt)/", entry_stop=100000)
# Applying a cut
dimuons_cut = muons["nMuon"] == 2
dimuons = muons[dimuons_cut]
# Getting the eta, pt and phi of each of the muons in the dimuon events
pt0 = dimuons["Muon_pt"][:,0]
pt1 = dimuons["Muon_pt"][:,1]
eta0 = dimuons["Muon_eta"][:,0]
eta1 = dimuons["Muon_eta"][:,1]
phi0 = dimuons["Muon_phi"][:,0]
phi1 = dimuons["Muon_phi"][:,1]
# Calculating the mass of the dimuon system
mass = np.sqrt(2 * pt0 * pt1 * (np.cosh(eta0 - eta1) - np.cos(phi0 - phi1)))
# Plotting the mass distribution using Hist + Matplotlib
fig, ax = plt.subplots()
masshist = hist.Hist(hist.axis.Regular(120, 0, 120, label="mass [GeV]"))
masshist.fill(mass)
masshist.plot1d(ax=ax)
ax.set_title("Dimuon Mass")
ax.set_xlabel("$m_{\mu\mu}$")
ax.set_ylabel("Count")
plt.show()
For the rest of this workshop, we will focus on the Z and Higgs boson. However, you might be wondering what those extra peaks are to the left of the Z peak. To emphasize these peaks, let’s make the plot logarithmic.
fig, ax = plt.subplots()
# Note: Making a logarithmic hist axis (i.e. hist with variable binning)
hist_data = hist.Hist(
hist.axis.Variable(np.logspace(np.log10(0.1), np.log10(1000), 100), name="mass", label="Invariant Mass [GeV]")
)
hist_data.fill(mass=mass)
hist_data.plot1d(ax=ax, histtype='step', color="red", linewidth=0.75)
ax.set_xscale("log")
ax.set_yscale("log")
ax.set_xlabel("Invariant Mass [GeV]")
ax.set_ylabel("Counts")
ax.set_title("Dimuon Invariant Mass Distribution")
plt.show()
Compare this to this cleaner dimuon mass spectrum with labels identifying what each peak corresponds to.
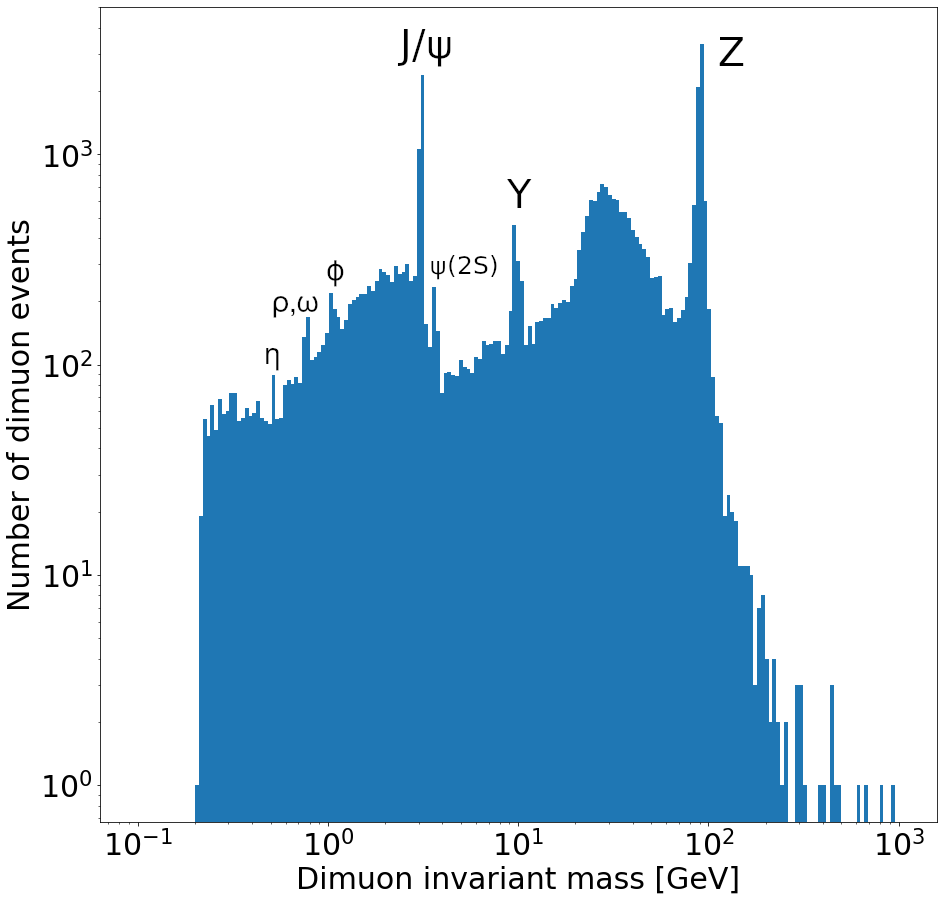
Fig. 7 Dimuon mass spectrum#
Exercise
Take the non-logarithmic version of the dimuon spectrum histogram plot we made and modify it by changing the following three things:
Change the color and style of the histogram line.
Add grid lines to the plot for better readability.
Adjust the x-axis range to focus on the region around the Z boson peak (e.g., 60 to 120 GeV).