Uproot I/O#
Introduction#
Scikit-HEP is a community-driven project that provides a comprehensive software ecosystem for high energy physics (HEP) analysis in Python. Its goal is to standardize and streamline data analysis workflows in HEP by offering a coherent collection of libraries that integrate with widely used tools such as Numpy, Pandas, Matplotlib, and Scikit-Learn. Among its major packages are:
Uproot: For reading and writing ROOT files without requiring ROOT.
Awkward Arrays: For the handling of jagged data structures.
Hist: For creating and manipulating histograms.
Vector: For manipulating and operating on vectors of different kinds in a high-performance manner.
Boost-Histogram: For fast, multi-dimensional histogramming.
Particle: For handling particle physics data, including properties and PDG codes.
Iminuit: For fitting.
In this tutorial, you will be introduced to the main components of the Scikit-HEP project, starting with Uproot and building from there. For more information on the Scikit-HEP project and the tools it offers, please visit the official Scikit-HEP Project Website.
ROOT Files#
ROOT files are a specialized binary file format developed for the efficient storage and analysis of large-scale data in high energy physics (HEP). They are structured hierarchically, much like a miniature filesystem, allowing for the organization of data into nested directories and subdirectories. Within these directories, ROOT files can store a wide variety of data types, including TTrees (which are analogous to tables or dataframes and are optimized for fast access to large datasets), histograms, graphs, and even user-defined objects. This flexible structure makes ROOT files particularly well-suited for complex experimental data, where different types of information (e.g., event records, calibration constants, and analysis results) need to be stored together in a single, organized file.
An example ROOT file structure can be seen in Fig. 5.
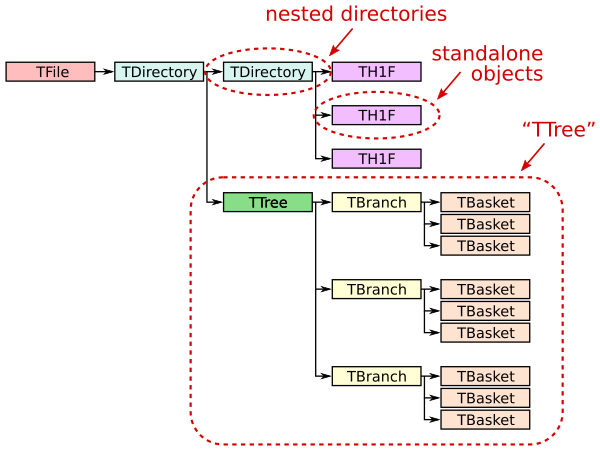
Fig. 5 ROOT file structure example.#
Let’s look a bit more closely at what each part of this example ROOT file are.
TDirectorys are container objects that act like a directory in a filesystem. I can hold other objects such as histograms, TTrees, or even other TDirectories.
TTrees are a high-performance data structure designed with storing large tabular datasets in ROOT files. It is conceptually similar to a table or a DataFrame, where each row (i.e., “entry” or “event”) represents a single data record, and each column (i.e., “branch”) holds a specific variable or array of variables.
TBranches corresponds to a column in a TTree. Each contains data for a specific variable or set of variables. They can store simple types (like numbers) or complex objects (like arrays or custom classes).
A TBasket is a chunck or block of data in a TBranch. They allow for more efficient access to parts of the data without having to load the entire branch into memory.
Uproot#
Uproot allows us to read and write ROOT files. It interacts with Numpy, Pandas as well as the packages offered by Scikit-HEP. It was created to not have to use ROOT in order to quickly work with ROOT files, which can be slow to load.
Opening a File#
To move forward, run the following cells to import Uproot and to download the sample data. This data is part of the skhep_testdata package which is another Scikit-HEP package which provides example files for testing and development.
# Run this cell to import Uproot
import uproot
import skhep_testdata
# Downloads test file and returns path to it
filename = skhep_testdata.data_path("uproot-Event.root")
file = uproot.open(filename)
file
This file object actually represents a directory and its contents are accesible through a dict-like interface. Let’s see what keys is has available.
file.items()
We can see tha it contains multiple values, each of different type. The types seen here are:
TProcessID:ROOT class that keeps track of process IDs in ROOT files. It is used internally by ROOT to manage object and their references, ensuring that object have unique identifiers across files or sessions. Typically useful for analysis.
TH1F:One-dimensional histogram with floating-point bin contents.
TTree:ROOT class used for efficient storage and access of large datasets.
Can be conceptualized as a table in a database of a DataFrame in pandas, where each column (branch) can contian different types of data, and each row (entry) corresponds toa single event or datapoint.
If it too large to fit in memory a TBranch can be broken down in to TBaskets which are batches of data. They are the smallest unit to read from a TTree.
We can easily read the histograms and utilize useful method provided by Uproot to convert the data to something more friendly, like NumPy or Awkawrd arrays (more on that later). For instance, if we want to do the former, we can access the histogram using the dict-like interphase you should already be familiar with:
Reading the histogram#
h = file["hstat;1"]
h
That doesn’t look like a histogram! If we want to visualize it, we can use the to_hist method. The output of this method is an object of type hist.Hist which is visualized in a Jupyter Notebook in a simplified way if just displayed directly (we will discuss the hist library in more detail later!).
h.to_hist()
If we want to properly plot this histogram and be able to modify how it looks, we can use the plot method of the hist.Hist object. This method uses matplotlib to make a nice looking plot which we can then modify in any way we wish.
# Using the hist Scikit-HEP library (more on that later...)
h.to_hist().plot(linewidth=0.75, color="red")
We can also convert the histogram to NumPy objects by using the to_numpy method. This method gives us a tuple. The first element is an array with the height of each bin, and the second element is an array with the edges of the histogram bins.
# Converting the histogram object to numpy arrays
h.to_numpy()
# First array is the data, second one is for bins
We can also use these arrays to make a plot of this histogram manually with matplotlib.
# We can then use plot this data using matplotlib
import matplotlib.pyplot as plt
hist_data, bin_edges = h.to_numpy()
bin_centers = (bin_edges[:-1] + bin_edges[1:]) / 2
plt.hist(bin_edges[:-1], bin_edges, weights=hist_data, histtype="step", color="red", linewidth=0.75)
plt.show()
The hist.Hist object also lets us directly accessthe values, errors and bin edges.
print(h.values())
print(h.errors())
print(h.axis("x").edges())
Accesing the TTree#
The TTree present in this example file contains simulated collisions data. To get us started, lets read the data using the dict-like interphase.
t = file["T;1"]
t
As you can see, directly printing t is not very useful and does not gives us much insight into the actual contents of the TTree. In order to get a glimpse of the data, it conveniently has a method called show which gives you a list of the name of each branch, as well as the type of data that is contained in each branch.
t.show()
If the large output from the show method is not to your liking, you can also use the keys method (more dict-like interphase!) to just get a list of the names of each field. Then, once you identify the one you are interested in, you can do the following to get more information on that particular branch.
# Other ways to get the same information
print(t["event/fNtrack"].typename)
print(t["event/fNtrack"].interpretation)
Suppose you already know the exact branch you want to access, and you just want to work with the data. To do that, you need to use the array method for a particular branch, which will return a special type of array.
t["event/fNtrack"].array()
Notice that this is not a regular Numpy array, but is in fact a new class of object. This is an Awkard array. We will see more of them later and see just how powerful they are, but for now just know that these arrays solve the limitation we saw Numpy arrays have: Awkward arrays can store jagged data (i.e. it can contain sub-arrays of different sizes).
type(t["event/fNtrack"].array())
t.keys()
The data we have at hand at the moment does not contain anything that would allow us to see this in action, but we can synthesize an example. We will see what other things Awkward arrays allow us to do later.
import awkward as ak
arr = ak.Array([
[1, 2],
[1, 2, 5, 8],
[],
[2, 5, 8, 2, 5, 8]
])
type(arr[0])
arr
One important thing to note is that not all data in a TTree can be loaded using into Awkard arrays. While Uproot and Awkward Arrays provide powerful tools for reading and manipulating data from ROOt TTrees in Python, there are certain limitations. For instance:
Unsupported Data Types: Some complex or custom ROOT data types (such as user-defined C++ classes, certain objects, or containers) may not be fully supported by Uproot or may not map cleanly into Awkward Arrays.
Unusual Branch Structures: TTrees with deeply nested or highly irregular structures, or those using features specific to ROOT (like pointers, references, or certain compression schemes), might not be accessible or interpretable outside of ROOT itself.
ROOT-Specific Functionality: Features like friend trees, certain types of object references, or on-the-fly C++ computations (via ROOT’s TTree::Draw or TTree::Scan) are not available in Uproot/Awkward.
In such cases, you may need to use the ROOT framework directly (typically via PyROOT or C++) to access, interpret, or process the data. Uproot and Awkward Arrays are best suited for standard, well-structured TTrees with basic data types (numbers, arrays, simple objects) and are not a complete replacement for all ROOT functionalities.
Writing to a ROOT file#
Uproot can not only read ROOT files, but it can also write them too! To do this, the file must be opened first. We can choose to create a completly new file to open or update an existing one. The funtions we can use to open a ROOT file to write to it are:
uproot.recreate(): Creates a new ROOT file with the given filename. If it already exists, it will be overwritten by an empty ROOT file of the same name. Returns a file handle that can be used to write data.uproot.update(): Opens an existing ROOT file in “update” mode. It is used for modifying existing files without deleting them. Returns a file handle that can be used to write data.
For instance, we can create a file called newrootfile.root in the following way.
myfile = uproot.recreate("newrootfile.root")
myfile
!ls newrootfile.root
You can then use the dict-like interphase of the myfile object to add things to the root file! For instance, we could store a string in the file.
# Adding a string
myfile["some_str"] = "Wow! I added this to a ROOT file myself!"
print(f"Keys: {myfile.keys()}")
myfile.values()
Side note: note that if we re-write the string in the ROOT file, it appears as if a new element is added with a new suffix ;2. What’s actually happening is that the old value is conserved, but you can only access it by specifying that you want the value with key some_str;1. If you try to access the value with key some_str, it will default to the latest version of the value.
myfile["some_str"] = "I added the same key again, but with a different value!"
print(f"Keys: {myfile.keys()}")
myfile.values()
myfile["some_str;1"] # Note the versioning
myfile["some_str;2"]
myfile["some_str"]
Let’s now add something a bit more interesting: a histogram! If we already have a hist.Hist object, or a histogram that is already in another ROOT file, we can copy that to our own ROOT file.
# Adding a histogram
myfile["some_histogram"] = file["hstat;1"]
myfile.values()
Alternatively, we can pass a tuple where the first element is an array representing the height of the bins, and the second element corresponds to the edges of these same bins. Just as an illustrative example, lets make a normal distribution that we can generate with NumPy.
import numpy as np
hist_data = np.histogram(
np.random.normal(0, 1, 1000000)
)
hist_data
This time, instead of placing the histogram at the root directory of the ROOT file, lets put it in a sub-directory. Doing this is as easy as giving the path and name of the histogram you are introducing into the ROOT file using the dict-like interphase.
# Adding a histogram within a nested directory
myfile["nested_directory/another_histogram"] = np.histogram(
np.random.normal(0, 1, 1000000)
)
myfile["nested_directory/another_histogram;1"].to_hist().plot()
Lets now add a TTree to our file. We can do this in two ways. First, we can use the dict-like interphase as we have been doing so far, and pass a dictionary as the value. Each key of the dictionary will correspond to the name of the TBranch that forms part of the TTree, and the value for each key corresponds to the actual data.
# One way to add branches
myfile["tree1"] = {
"x": np.random.randint(0, 10, 1000000),
"y": np.random.normal(0, 1, 1000000),
}
If you wanted to add more data to this TTree, you can use the extend method.
myfile["tree1"].extend(
{"x": np.random.randint(0, 10, 1000000), "y": np.random.normal(0, 1, 1000000)}
)
myfile["tree1"].extend(
{"x": np.random.randint(0, 10, 1000000), "y": np.random.normal(0, 1, 1000000)}
)
Another way to add data to instantiate a TTree and store data in it is by using the mktree (i.e., “make tree”) method. This way of adding data can be better, as it gives you more control over the type of each TBranch (notice that we didn’t specify what type of data we put in the tree when we used the previous method; we left the computer to figure that out by itself!).
# Another way to add baskets
myfile.mktree("tree2", {"x": np.int32, "y": np.float64})
for _ in range(20):
myfile["tree2"].extend(
{"x": np.random.randint(0, 10, 1000000), "y": np.random.normal(0, 1, 1000000)}
)
Once we have stored data in our TTree, we can check the number of baskets into which the data is divided.
# Each call to extend create a new basket in the `tree2` branch
myfile["tree2"].num_baskets
The list of data types that can be written to files can be found here: link
Moving on#
We now have some of the basic knowledge required to work with ROOT files using Uproot. We will now go on to apply what we have learned to explore and analyze some simulated data!